
以前、SynologyのCSI Driverを使い、おうちクラスタで使えるボリュームを作成してみたのですが、SynologyのNASではLUNの払い出し数に上限があり、色々使っていると、あっという間にPersistentVolumeが作れない状態になってしまいました。

そのため、今回はクラスタの各ノードにあるHDDを有効活用すべく、rook-cephクラスタを構築しようとしてみた記事です。
Rook Cephとは?
詳細は省きますが、Cephは、分散ストレージを提供するためのOSSであり、Rookは、Kubernetes上でストレージを管理するためのOSSです。
つまり、Rookを使い、Kubernetesクラスタの上でCephクラスタを構築する。というような形になっており、両者は「組み合わせて使う」ものになっています。
一応、Rook自体は、「他の分散ストレージのOperator」としても利用できる。という認識であったのですが、公式サイトではCeph以外の記述がありません・・・方針変更でもあったのでしょうか。

もちろん、手でCephを構築することも可能です。
Rook自体はOperatorなので、使用するリソースは大したことがないのですが、Cephの方がかなり厳しかったです。最小システム要件は、こちらのサイトでかなり分かりやすくまとまっていました。

Rook Operatorのインストール
Cephクラスタを構築する前に、Rook Operatorをインストールします。
といっても、単なるOperatorですし、Helm Chartもありますので、特に何も気にせずにインストールします。
helm repo add rook-release https://charts.rook.io/release
helm install -n rook-ceph rook-ceph rook-release/rook-ceph --create-namespaceCephクラスタの内容物メモ
Cephクラスタの構成要素 – RADOS
Cephクラスタは、物理的に存在するHDDやSSDといったディスクを、OSDという単位で管理します。
また、OSDはMonitorによって監視・管理されています。
OSDは複数存在することが前提で、あるデータを書き込もうとすると、複数のOSDにデータがレプリケーションされます。
そのため、1つのOSDが故障したとしても、別のOSDにあるデータに対してIOを継続できます。
MonitorはOSDのデータがどこに存在するかも管理しており、CRUSHというアルゴリズムを使い配置されます。
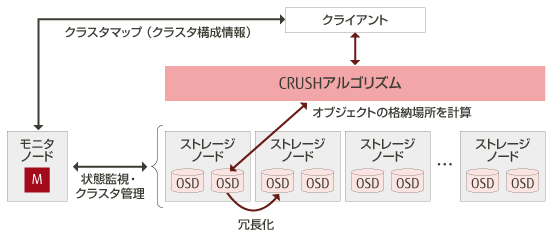
このような形で、複数の物理ストレージデバイスを持つクラスタを作成します。
これをRADOSと言います。
Cephクラスタの構成要素 – RBD
RADOSをいい感じに操作して、Linuxのファイルシステムにマウントして使用できるようにするインターフェースがRBDです。
AWSやGCPで、VMに接続して、OSの起動などに利用するディスクとして「ブロックストレージ」などと呼ばれますが、RADOSをブロックストレージとして利用するためのコンポーネントがRBDです。
Kubernetesクラスタで利用する際は、このRBDが1つの鍵になります。
また、今回はRook Cephクラスタで利用することだけを考えているので、説明は端折りますが、S3互換のオブジェクトストレージとして利用可能な「RADOSGW」や、POSIXファイルシステムを提供する「CephFS」も存在します。
RBDは、RADOSの「プール」を作成し、そのプールの中に「イメージ」を作成します。
構築したCephクラスタの上でコマンドを実行してみます。
実際に、プールとイメージが作成されていることがわかります。
(base) kentaro@BeahLaptop-5 ~ % ceph osd pool stats
pool ceph-blockpool id 1
client io 2.3 KiB/s rd, 87 KiB/s wr, 0 op/s rd, 4 op/s wr
pool ceph-objectstore.rgw.control id 2
nothing is going on
pool ceph-filesystem-metadata id 3
client io 1.2 KiB/s rd, 2 op/s rd, 0 op/s wr
pool ceph-filesystem-data0 id 4
nothing is going on
(base) kentaro@BeahLaptop-5 ~ % rbd list ceph-blockpool
csi-vol-0bb97fd4-980d-4e8d-97f8-e4d160837e3a
csi-vol-14ddc51b-b235-44c4-8001-6301cdee0692
csi-vol-1fa20774-b0e6-480d-a8f8-3bce976853af
csi-vol-21244f98-4049-4b35-acf5-766ef81adcc0
csi-vol-4b237a1a-8174-4a7a-bb94-c58c2aad4939
csi-vol-4e4c5432-7c9e-4e63-b04c-6fcc0de9c8f3
csi-vol-5e1d14d9-1917-4e70-b1ab-f9d2488d7c65このイメージを、Linuxなどがマウントすることで、ストレージとして利用可能になります。
Cephクラスタの構築
Cephのクラスタ構築は、手作業で行う場合は、OSDやRBD、Monitorなどの構成も手作業になりますが、Rookを使うことで、Kubernetesの仕組みにより、簡略化することができます。
Helm ChartでのCeph Clusterのインストール
Cephクラスタの構築でも、Helm Chartが役立ちます。
helm install -n rook-ceph rook-ceph rook-release/rook-ceph-cluster --create-namespaceこの時、Valuesは以下のようにしました。
cephClusterSpec:
storage:
useAllNodes: false
useAllDevices: false
nodes:
- name: "worker-01"
devices:
- name: "sda"
- name: "worker-02"
devices:
- name: "sda"
- name: "worker-06"
devices:
- name: "sda"
toolbox:
enabled: truetoolboxを使うと、Cephクラスタ上の操作を直接行えます。
デバッグなどに便利なので、入れておきましょう。
大事なのはcephClusterSpec.storage周りです。
今回、一部のノードにのみOSDを構成するため、自動で全てのノードやデバイスがOSDにすべきか判定する対象とはせず、手動でノードとOSDに利用するデバイスを指定します。
cephClusterSpec.storage.nodes[x].devices[y].nameは、マシンに接続しているディスクの名前を指定するのですが、このようにして確認します。
clusteradmin@worker-06:~$ sudo fdisk -l
Disk /dev/loop0: 63.91 MiB, 67014656 bytes, 130888 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk /dev/sda: 3.64 TiB, 4000787030016 bytes, 7814037168 sectors
Disk model: WDC WD40EZAX-00C
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 4096 bytes
I/O size (minimum/optimal): 4096 bytes / 4096 bytes
Disk /dev/sdb: 465.76 GiB, 500107862016 bytes, 976773168 sectors
Disk model: Samsung SSD 860
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: gpt
Disk identifier: 8353763C-AA63-4E63-9100-3CEE52A29C41
Device Start End Sectors Size Type
/dev/sdb1 2048 2203647 2201600 1G EFI System
/dev/sdb2 2203648 976771071 974567424 464.7G Linux filesystemここで言うところの/dev/xxxxxx部分を使用します。
なお、/dev/は省略可能みたいです。
OSDとして利用するディスクは、パーティションマップなどがない、空のディスクである必要があります。
そのため、上記の例だと、GPTなどでフォーマットされている/dev/sdbなどは、利用できません。ddコマンドなどを使い、パーティションを完全に削除します。
Ceph Clusterをデプロイしたその後
rook-ceph-clusterのHelm Chartによってデプロイされるものの正体は、CephClusterリソースと、それにまつわるStorageClass、PrometheusのRuleなどです。
CephClusterが作成されると、rook-ceph operatorによって、OSDなどのPodが作成されます。
OSDのPodは、ホストの/devをマウントしており、物理的なデバイスをPodから触ることができるようになっています。
Helm Chartによってデプロイされるものについては、ArtifactHUBなどでも確認ができます。

アホほどリソースが食われる?
意気揚々と、Cephクラスタをデプロイしましたが、問題が発生しました。
Cephの各コンポーネントが、CPUやメモリをモリモリRequestしていくので、他のアプリケーションのPodが入る余地がないどころか、Cephのコンポーネントも一部スケジューリングできなくなってしまいました。
そこで、先程のcephClusterSpecに、以下のような制約を加えます。
resources:
api:
requests:
cpu: "500m"
memory: "512Mi"
limits:
memory: "512Mi"
mgr:
requests:
cpu: "500m"
memory: "512Mi"
limits:
memory: "512Mi"
mon:
requests:
cpu: "500m"
memory: "1Gi"
limits:
memory: "1Gi"
osd:
limits:
memory: 4Gi
requests:
cpu: 500m
memory: 4Giこれにより、何とかコンポーネントはデプロイされるようになりました。
おうちが地獄化
それでも、他のアプリケーションがデプロイできるだけの余裕はないため、純粋に物理マシンを増やすこととなり、結果的に、PCが並んでいるだけのギリギリ一般のご家庭が、「おうちデータセンター」の様相を呈し始めました。

銀色のMac miniは、HAProxyが動いている、いわゆる「ロードバランサー」で、左上のラズパイ×3はKubernetesのControl Planeです。
逆に言えば、それ以外は全てWorker Nodeです。
一番右のデカいPCは、元々サーバー用途として自作→クラウド化した際にWindowsマシンへ→自宅回帰の流れの中のCeph構築のためにサーバーとして復帰したマシンです。
どれでもない、DELL製のPC×5は、中古PCとして購入しました。
横河レンタリースという法人向けリース会社が、リースアップされたPCをリファービッシュ品として販売しており、活用しています。

比較的安価で状態の良いものが手に入るので、自宅サーバーには結構良いのかもと思いました。
これらのノードは、いずれも1〜2万円/台程度で手に入っています。
デプロイ完了
必要なコンポーネントがデプロイし終わると、いよいよCeph ClusterのStatusがHEALTH_OKになります。
(base) kentaro@BeahLaptop-5 ~ % kubectl get cephclusters -n rook-ceph
NAME DATADIRHOSTPATH MONCOUNT AGE PHASE MESSAGE HEALTH EXTERNAL FSID
rook-ceph /var/lib/rook 2 19d Ready Cluster created successfully HEALTH_OK 29955281-2248-47a9-9e3c-3b13f9a8d2e5また、StorageClassや、CSIドライバーもデプロイされています。
(base) kentaro@BeahLaptop-5 ~ % kubectl get storageclass
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
ceph-block (default) rook-ceph.rbd.csi.ceph.com Delete Immediate true 19d
ceph-bucket rook-ceph.ceph.rook.io/bucket Delete Immediate false 19d
ceph-filesystem rook-ceph.cephfs.csi.ceph.com Delete Immediate true 19d
(base) kentaro@BeahLaptop-5 ~ % kubectl get pods -n rook-ceph
NAME READY STATUS RESTARTS AGE
csi-cephfsplugin-7qxgb 2/2 Running 1 (4d23h ago) 4d23h
csi-cephfsplugin-8hz22 2/2 Running 4 (4d23h ago) 19d
csi-cephfsplugin-bzg62 2/2 Running 0 4d22h
csi-cephfsplugin-jlq5s 2/2 Running 0 19d
csi-cephfsplugin-jwzb4 2/2 Running 1 (5d ago) 5d
csi-cephfsplugin-provisioner-7ff6cd7ddf-4sbbb 5/5 Running 0 4d23h
csi-cephfsplugin-provisioner-7ff6cd7ddf-n2nsx 5/5 Running 1 (4d23h ago) 4d23h
csi-cephfsplugin-xtbw8 2/2 Running 0 19d
csi-rbdplugin-87j98 2/2 Running 0 19d
csi-rbdplugin-9c4rm 2/2 Running 1 (4d23h ago) 4d23h
csi-rbdplugin-9dzkx 2/2 Running 0 19d
csi-rbdplugin-f9hhq 2/2 Running 1 (5d ago) 5d
RBDをPVとして利用する
ここまで来たら、いよいよPersistent VolumeとしてRBDを利用します。
テスト用にPVCを作成します。
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: test-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Giそして、PVCをマウントするPodも用意します。
apiVersion: v1
kind: Pod
metadata:
name: test-pod
spec:
containers:
- name: test-container
image: nginx
volumeMounts:
- name: test-volume
mountPath: /usr/share/nginx/html
volumes:
- name: test-volume
persistentVolumeClaim:
claimName: test-pvckubectl applyすると、PVも作成されます。
(base) kentaro@BeahLaptop-5 ~ % kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS VOLUMEATTRIBUTESCLASS REASON AGE
pvc-351da037-1ae9-44ea-b5f7-cc95a7b1632b 1Gi RWO Delete Bound default/test-pvc ceph-block <unset> 36sPodも作成されました。
(base) kentaro@BeahLaptop-5 ~ % kubectl get pods
NAME READY STATUS RESTARTS AGE
test-pod 1/1 Running 0 93sコンテナの中の、永続ボリュームがマウントされている領域にファイルを作成します。
(base) kentaro@BeahLaptop-5 ~ % kubectl exec test-pod -it -- bash
root@test-pod:/# echo "Hello World" >> /usr/share/nginx/html/index.html
root@test-pod:/# cat /usr/share/nginx/html/index.html
Hello WorldPodを再作成します。
(base) kentaro@BeahLaptop-5 ~ % kubectl replace -f test-pvc.yaml --force
pod "test-pod" deleted
pod/test-pod replaced再作成したPodで、同じファイルが観られるか確認します。
(base) kentaro@BeahLaptop-5 ~ % kubectl exec test-pod -it -- bash
root@test-pod:/# cat /usr/share/nginx/html/index.html
Hello World無事にファイルが永続化されました!
所感
CephはOpenStackのストレージバックエンドとしても利用されている、しっかりしたストレージ基盤を提供します。
手作業での運用だとつらみも多いですが、Kubernetesの仕組みの中でいい感じにクラスタを構成できるので、後から思い返せば簡単に構築できました。
一方で、Cephで何かトラブった時のトラブルシューティングは、かなりレイヤーの低い知識も絡むため、なるべくトラブりたくないな・・・というのが感想です。
何はともあれ、いい感じの安定したストレージ基盤が手に入ったのはとても良かったです。
Synology CSIの制限で、移行できていなかったブログやMastodonも、これで安心して移行することができました。
今後、HDD→SSDへの換装や、10G化なども取り組みたいところですが、まずは一旦これで・・・
